Bodyguard
Flask Status: Distilling 🧪
Overview
Bodyguard is a security analysis service that detects malicious prompts and potential attacks in LLM inputs. It identifies prompt injection attacks, social engineering attempts, and other security threats before they can reach your AI systems or tools. Each prompt receives a threat score from 0 to 1, where 1 indicates extreme risk, and a set of findings, that can aid decision-making.
Unlike rule-based security systems, Bodyguard uses an LLM to understand the semantic intent behind prompts, catching sophisticated attacks that might bypass traditional filters.
Getting Started
Try it out here (COMING SOON). For detailed usage instructions, see the implementation guide.
Use Cases
- End-user-facing chatbots, help-bots, etc
- Automatic email readers/responders
- Automatic processors of any untrusted input
- Twitterbots, Discord bots, or any other social media automation
Key Features
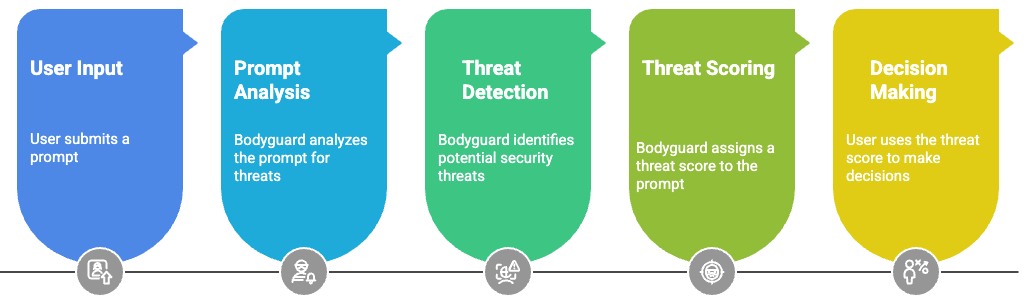
- Prompt Injection Detection: Identifies attempts to override system prompts or instructions
- Information Extraction Prevention: Catches attempts to extract sensitive data or system information
- Malicious Function Call Detection: Recognizes dangerous tool-calling patterns
- Social Engineering Defense: Detects manipulation tactics and deceptive requests
- Threat Scoring: Provides numerical threat scores (0-1) for risk assessment
- Multiple Deployment Options: Available as CLI tool, HTTP server, and client library
Integration Notes
Bodyguard works as a complementary layer with other Civic Labs tools:
By implementing the MCP Hooks interface, Bodyguard can be used to wrap MCP server responses, providing protection against external inputs
Use with Guardrail Proxy for defense in depth, Bodyguard analyzes prompts while Guardrail enforces rules
Deploy before MCP Hub to pre-screen all requests to your MCP tools
Integrate with Civic Knowledge to protect internal systems and LLMs from potentially dangerous data sources
Status
This flask is currently distilling: Bodyguard is actively deployed in test environments and showing strong detection rates for common attack patterns. We're expanding the threat detection capabilities and optimizing response times. Docker images are available for easy deployment. Contact us if you'd like to test it with your specific use cases.
Resources
- Implementation Guide - Deployment and API documentation (requires access)
- GitHub Repository (private - request access)
- Docker Image (contact for access)